
Đây là phần 3 trong series 3 phần “Sập Server có phải muôn đời”.
- Làm gì khi hệ thống sập bất ngờ – Xách quần lên công ty
- Viết post-mortem sau khi xử lý sự cố – Đừng chỉ trích hay đổ lỗi
- Những phương pháp phòng chống/monitoring – Giúp anh em ngủ ngon không lo server sập
Ở 2 phần trước, mình đã chia sẻ về những việc cần làm khi hệ thống sập bất ngờ, nên viết post motern như thế nào để tránh gặp phải những sai lầm tương tự.
Tuy vậy, như các cụ đã nói “phòng bệnh hơn chữa bệnh”, phòng chống hệ thống sập thì tốt hơn là chờ hệ thống tèo rồi mới sửa chứ nhỉ. Do vậy, ở kì này, mình sẽ chia sẻ những kinh nghiệm phòng chống nhé.
Tại sao không nên chờ “nước đến chân mới sửa”?
Phần đông những hệ thống của doanh nghiệp, của các công ty lớn đều có 1 cái gọi là SLA (Service-Level Agreement). Nói nôm na, nó là 1 bản cam kết chất lượng dịch vụ.
Thông thường, trong SLA, các dịch vụ đều phải high availbility tầm 99.9% hoặc 99.99%, tức là 1 tháng chỉ được sập tầm 5 phút (99.99) hoặc hoặc 45 phút (99.9%). Nếu thời gian sập quá mức này, vi phạm SLA, đơn vị cung cấp sẽ bị mất uy tín, đồng thời phải bồi thường 1 khoản không hề nhỏ.
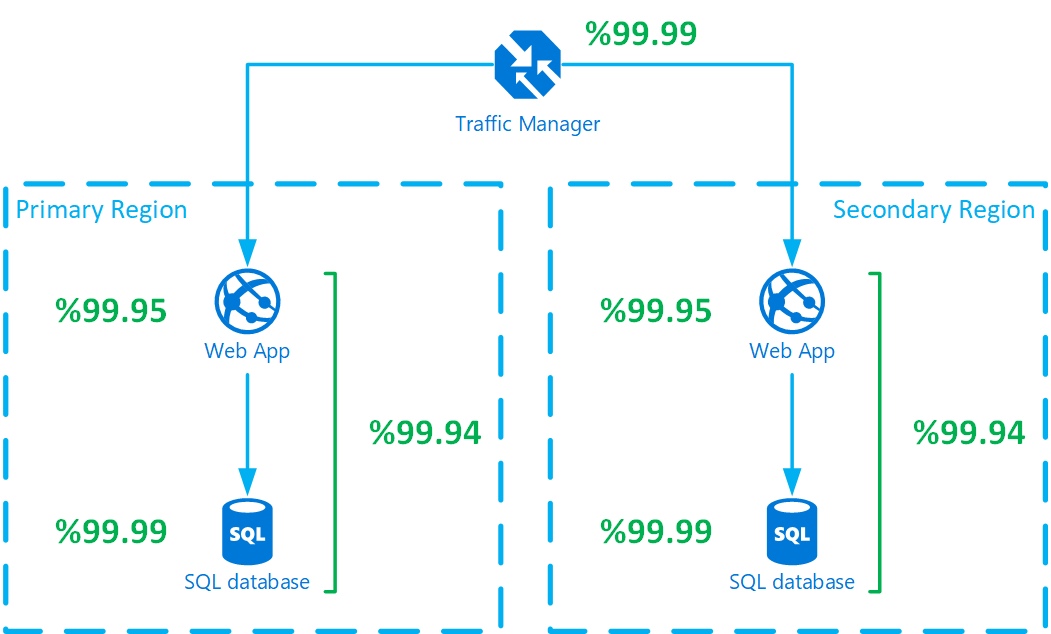
Vì vậy, nếu chờ hệ thống sập rồi mới sửa thì gần như không kịp! Mấy anh dev phải nghĩ cách phòng chống, tìm bệnh trước, để có thể sửa chữa hệ thống khi nó mới hắt hơi/sổ mũi, chứ không đợi tới lúc nó ngủm luôn nha!
Làm sao để anh em ngủ ngon, không lo server sập
Đây là những kinh nghiệm xương máu, rút ra từ mồ hôi nước mắt các thế hệ sysadmin/developer/devops ở các công ty nha.
Có hệ thống failover
Failover là 1 trong những biện pháp cơ bản nhất, đơn giản nhất để tránh server sập. Nói đơn giản, failover system tức là 1 hệ thống … dư thừa, chạy song song với hệ thống chính.
Khi hệ thống chính bị sập, ta sẽ tự động chuyển người dùng qua hệ thống failover này, để tránh làm gián đoạn dịch vụ. (Giống như khi các bạn đi mát xa, mấy em nhân viên đẹp bị nghỉ ốm, failover sẽ là mấy em nhân viên ế khách ra phục vụ các bạn vậy á).
Đa phần các database có hỗ trợ failover qua cơ chế master/slave. Khi master có vấn đề thì slave sẽ được promote lên làm master. Ở tầm webserver, ta thường dùng load balancing để cân bằng tải trong 1 cluster nhiều server, 1 server sụp cũng không ảnh hưởng hệ thống.
Cách này khá hiệu quả, nhưng có thể sẽ khá… tốn kém, vì ta phải bỏ chi phí bảo trì, vận hành thêm hệ thống phụ mà không dùng tới.
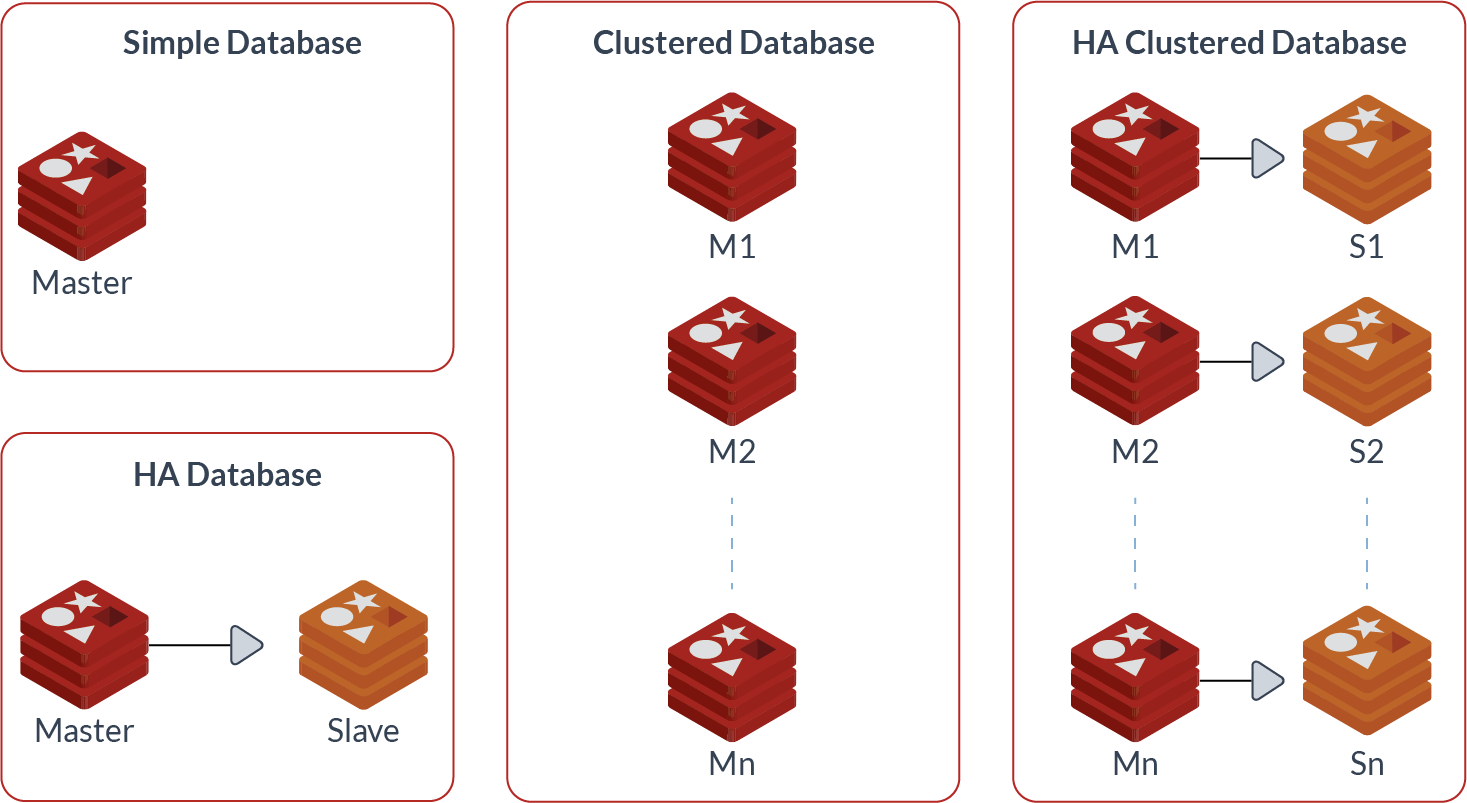
Có monitoring, notification khi thấy có điều bất thường
Thông thường, một hệ thống sập sẽ có 1 số dấu hiệu bất thường trước khi sập. Do vậy, ta phải setup monitoring, có dashboard để dễ dàng nhận thấy những bất thường trong hệ thống.
Thông thường, người ta hay monitor những thứ như CPU/RAM, dung lượng ổ cứng. Nếu là web thì họ sẽ monitor thêm số lượng API được gọi, thời gian API chạy, status trả về là 200 hay 500. Ở tầm cao hơn thì họ monitor những thứ thực tế như số cuốc xe đặt trong 10 phút, số đặt phòng trong 1 giờ v…v
Với vô số những thứ cần monitor như vậy, ta cần có 1 cái dashboard để dễ dàng quan sát tình hình chung. Tất nhiên, không phải ai cũng rảnh mà ngồi nhìn dashboard cả ngày, nên ta sẽ phải setup 1 số notificaiton luôn.
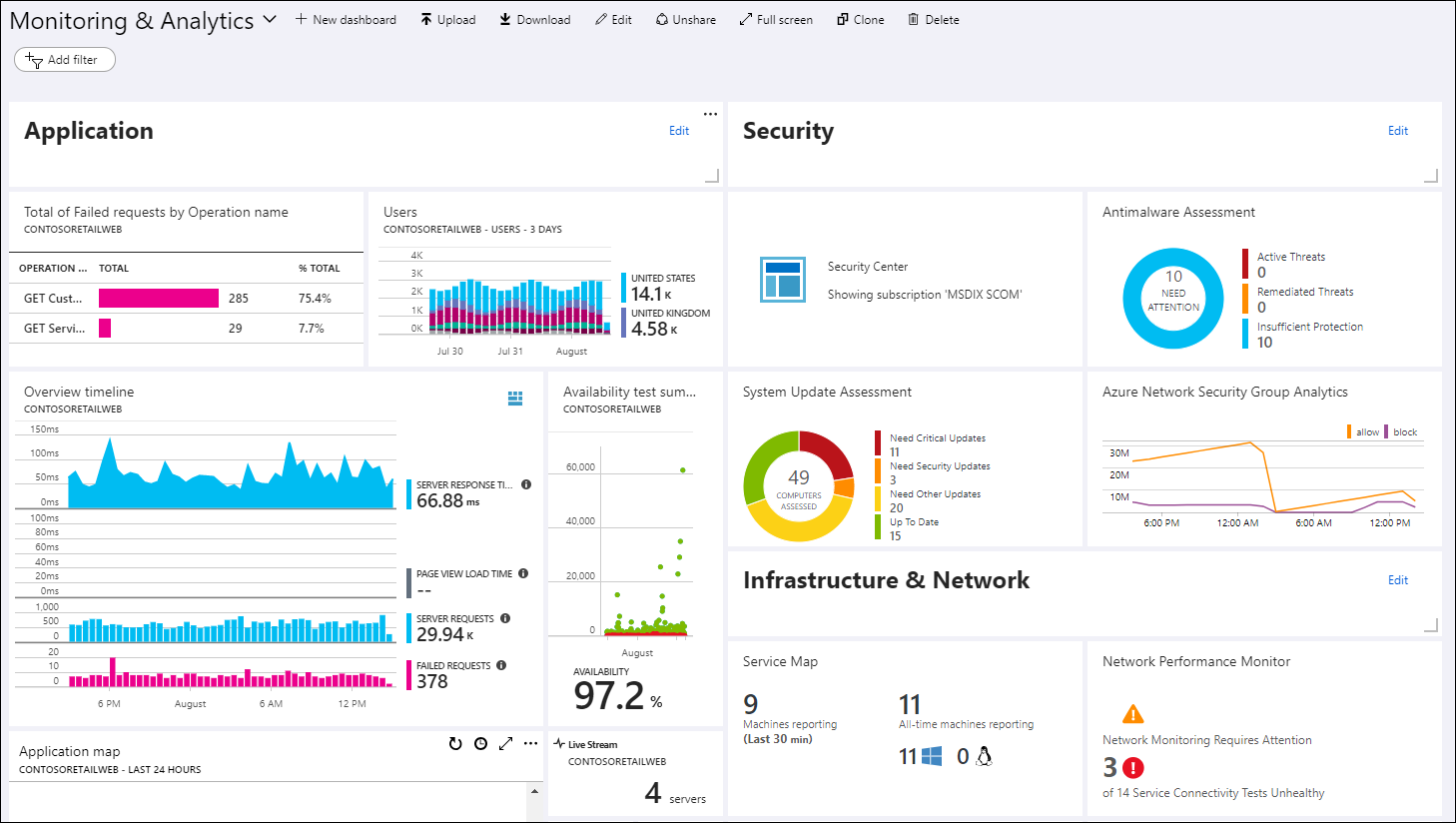
Ví dụ, khi CPU/RAM lên quá cao, hoặc khi lượng order tụt xuống nhiều, hệ thống sẽ notify bằng cách gửi SMS/email đến mấy anh DevOps để họ vào kiểm tra, trước khi người dùng phát hiện. Khi cần, hệ thống cũng có thể tự recover bằng cách tăng thêm instance, restart server v..v
Tất nhiên, notify quá nhiều sẽ làm chúng ta … lờn mặt, bỏ qua notification. Do vậy, phải làm 1 thời gian chúng ta mới biết nên theo dõi những thông số gì, notify khi nào nha.
Backup dữ liệu thường liệu – Nhớ diễn tập restore
Hệ thống sập thì có thể chạy lại được. Nhưng dữ liệu mà mất là coi như … công ty đi đứt. Do vậy, việc lưu trữ, backup dữ liệu là vô cùng quan trọng!
Nếu công ty bạn sử dụng Cloud, đa phần các dịch vụ database đều đã có tự động back-up/recovery, chỉ cần tốn thêm phí là xong. Nếu tự chạy, các bạn nên có script backup mỗi ngày, mỗi tuần hoặc… mỗi giờ nếu cần thiết!
Ngoài ra, điều quan trọng hơn là … phải kiếm tra xem dữ liệu đã back-up đấy có đúng không, có restore lại được hay không! Mình thấy có nhiều chỗ back-up dữ liệu cả năm nhưng… chưa restore bao giờ, tới lúc cần restore thì mới thấy restore rất chậm, tool restore bị lỗi, dữ liệu back-up bị thiếu.
Do vậy, có back-up là tốt, nhưng phải nhớ kiểm tra xem back-up đó có hoạt động được hay không nhé.
Test đủ, test kĩ, deploy dần dần
Đương nhiên, nếu hệ thống sụp là do bug, do lỗi của developer, thì để hệ thống ổn định, chúng ta phải tìm cách phát hiện, tiêu diệt những bug này trước khi hệ thống lên production.
Các bạn tester sẽ test để tìm lỗi hệ thống. Tuy vậy, khi hệ thống lớn, nhiều tính năng, việc test này sẽ vô cùng mất thời gian.
Do vậy, người ta thường dùng unit test để test code, kết hợp với automation test để test toàn bộ hệ thống. Thông thường, trước khi code được merge, được deploy lên staging, các test này sẽ được chạy để đảm bảo hệ thống không bị lỗi.
Ngoài ra, phần đông nguyên nhân sự cố thường là do… developer sửa code (thêm tính năng mới, fix bug). Do vậy, người ta thường release bản beta/canary để một số người dùng test trước. Ở hệ thống web, họ cũng hay dùng feature flag để test tính năng mới ở 1 số người dùng/khu vực, trước khi phổ cập cho toàn bộ người dùng.
Nhờ cách này, nếu phiên bản beta, tính năng mới bị lỗi, số lượng người bị ảnh hưởng sẽ ít hơn rất nhiều! Team dev sẽ có thời gian chỉnh sửa cho phù hợp trước khi release bản chính thức.
Tạm kết
Phù, series này khá dài, cảm ơn các bạn đã chịu khó đọc đến hồi kết.
Trong bài này, mình chỉ nói sơ 1 số biện pháp phòng chống, giữ cho hệ thống hoạt động ổn định thôi. Nếu nói chi tiết, chắc là phải mất vài cuốn sách + mấy khoá học vẫn chưa hết. Do vậy, các bạn có thể tìm hiểu thêm về high availability system và DevOps nha.
Lời cuối cùng của series: Nếu hệ thống của bạn có bị lỗi hay bị sụp, cũng đừng quá buồn, hay trách móc team mình. Hệ thống các công ty lớn còn có lúc sụp, nên của ta bị sụp cũng bình thường.
Hãy xem mỗi lần sụp là 1 lần được học hỏi, là cơ hội để ta làm hệ thống ổn định hơn nhé!
Discover more from Từ coder đến developer - Tôi đi code dạo
Subscribe to get the latest posts sent to your email.
