
Toàn bộ series Nhận diện Idol:
- Phần 1 – Chuyện ngày xưa – về sự ra đời của Nhận Diện Idol
- Phần 2 – Kiến trúc và các công nghệ sử dụng
- Phần 3 – Nào mình cùng đi cào dữ liệu
- Phần 4 – Nhận diện khuôn mặt với Microsoft Cognitive Service
- Phần 5 – Testing thuật toán – Sự thật về độ chính xác 60-80%
- Phần 6 – Từ demo tới deploy – Vô Thai Kiếm (Serverless Architecture)
Ở bài trước, chúng ta đã submit dữ liệu để huấn luyện cho API. Bài này sẽ hướng dẫn các bạn cách sử dụng API này để viết một method nhận diện hoàn chỉnh.
Sử dụng API như thế nào?
Chúng ta sẽ viết một method như sau:
- Đầu vào (Input): URL của một ảnh bất kì
- Đầu ra (Output): Vị trí các khuôn mặt trong ảnh (để hiển thị) và tên của chủ nhân khuôn mặt
Trong phần 4 mình đã nói về cơ chế nhận diện khuôn mặt gồm 2 quá trình: Face Detection và Face Recognition. Hai quá trình này tương ứng với 2 API của Microsoft Cognitive API:
- Detect: Phát hiện khuôn mặt trong ảnh và vị trí các khuôn mặt này.
- Identity: Đầu vào là id của khuôn mặt và id của Person Group. Đầu ra là id của Person giống nhất.
Bắt đầu viết code thôi nào, nếu các bạn đã download project của mình ở bài trước thì sẽ thấy code đã có sẵn trong file test.js. Tuy vậy, mình sẽ giải thích một số hàm để các bạn dễ hiểu.
Đầu tiên, chúng ta khai báo thư viện và đọc thông tin từ một số file json cùng thư mục. (Nhớ bỏ file idol-person.json bạn có từ phần trước vào thay file của mình nhé).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // Sử dụng thư viện | |
| var request = require('sync-request'); | |
| // Đọc thông tin idol trong file filtered-idols.json và thông tin person đã lưu từ API | |
| var idols = require('./filtered-idols.json'); | |
| var idolPerson = require('./idol-person.json'); | |
| var falseData = require('./falseData.json'); | |
| let key = '91bc85*******'; // Thay thế bằng key của bạn | |
| let groupId = 'vav-idols'; |
Ta viết hàm detect, hàm này sẽ nhận vào URL một ảnh, trả ra khuôn mặt và vị trí của chúng.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // Phát hiện khuôn mặt trong ảnh (Face Detection) | |
| function detect(imageUrl) { | |
| console.log(`Begin to detect face from image: ${imageUrl}`); | |
| let url = `https://api.projectoxford.ai/face/v1.0/detect`; | |
| var res = request('POST', url, { | |
| headers: { | |
| 'Ocp-Apim-Subscription-Key': key | |
| }, | |
| json: { | |
| url: imageUrl | |
| } | |
| }); | |
| if (res.statusCode == 200) { | |
| var result = JSON.parse(res.getBody('utf8')); | |
| console.log(`Found ${result.length} faces.`); | |
| return result; | |
| } | |
| } | |
| // Kết quả của hàm | |
| [ | |
| { | |
| "faceId": "c5c24a82-6845-4031-9d5d-978df9175426", | |
| "faceRectangle": { | |
| "width": 78, | |
| "height": 78, | |
| "left": 394, | |
| "top": 54 | |
| } | |
| } | |
| ] |
Sau khi đã có ID của các khuôn mặt trong ảnh (faceID), ta dùng các id này làm input cho hàm identity. API sẽ so sánh các khuôn mặt, đưa ra ID của person có khuôn mặt gần giống nhất (trong mảng candidates).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // Tìm khuôn mặt giống nhất trong Person Group (Face Recognition) | |
| function identify(faceIds) { | |
| console.log(`Begin to identity face.`); | |
| let url = 'https://api.projectoxford.ai/face/v1.0/identify'; | |
| var res = request('POST', url, { | |
| headers: { | |
| 'Ocp-Apim-Subscription-Key': key | |
| }, | |
| json: { | |
| "personGroupId": groupId, | |
| "faceIds": faceIds, | |
| "maxNumOfCandidatesReturned": 1, | |
| } | |
| }); | |
| if (res.statusCode == 200) { | |
| console.log(`Finish identity face.`); | |
| return JSON.parse(res.getBody('utf8')); | |
| } else { | |
| console.log('Error'); | |
| console.log(res.getBody('utf8')); | |
| } | |
| } | |
| // Kết quả của hàm này | |
| { | |
| [ | |
| { | |
| "faceId":"c5c24a82-6845-4031-9d5d-978df9175426", | |
| "candidates":[ | |
| { | |
| "personId":"25985303-c537-4467-b41d-bdb45cd95ca1", | |
| "confidence":0.92 | |
| } | |
| ] | |
| }, | |
| { | |
| "faceId":"65d083d4-9447-47d1-af30-b626144bf0fb", | |
| "candidates":[ | |
| { | |
| "personId":"2ae4935b-9659-44c3-977f-61fac20d0538", | |
| "confidence":0.89 | |
| } | |
| ] | |
| } | |
| ] | |
| } |
Sau khi có ID của các person, ta tìm idol tương ứng có person ID từ file idol-person.json. Ta viết hàm recognize lần lượt gọi 2 hàm trên, tìm idol trong file json và format dữ liệu cho dễ sử dụng.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // Nhận diện vị trí khuôn mặt và tên idol từ URL ảnh | |
| function recognize(imageUrl) { | |
| console.log(`Begin to recognize image: ${imageUrl}`); | |
| var detectedFaces = detect(imageUrl); | |
| if (detectedFaces.length == 0) { | |
| console.log("Can't detect any face"); | |
| return; | |
| } | |
| // Sau khi đã phát hiện các khuôn mặt, | |
| // So sánh chúng với mặt đã có trong person group | |
| var identifiedResult = identify(detectedFaces.map(face => face.faceId)); | |
| var allIdols = identifiedResult.map(result => { | |
| // Lấy vị trí khuôn mặt trong ảnh để hiển thị | |
| result.face = detectedFaces.filter(face => face.faceId == result.faceId)[0].faceRectangle; | |
| // Tìm idol đã được nhận diện từ file idol-person. | |
| if (result.candidates.length > 0) { | |
| // Kết quả chỉ trả về ID, dựa vào ID này ta tìm tên của idol | |
| var idolId = result.candidates[0].personId; | |
| var idol = idolPerson.filter(person => person.personId == idolId)[0]; | |
| result.idol = { | |
| id: idol.userData, | |
| name: idol.name | |
| }; | |
| } else { | |
| result.idol = { | |
| id: 0, | |
| name: 'Unknown' | |
| } | |
| } | |
| return result; | |
| }); | |
| console.log(`Finish recognize image: ${imageUrl}`); | |
| return allIdols; | |
| } |
Kết quả của hàm recognize là một mảng chứa các vị trí các khuôn mặt, tên của chủ nhân khuôn mặt (Nếu trong ảnh có nhiều mặt thì mảng sẽ có nhiều phần tử).

Đây là hàm quan trọng nhất chương trình, viết xong nó là xong hết 80% rồi. Bây giờ chúng ta sẽ đánh giá độ chính xác của hàm này.
Phần test bên dưới không quan trọng lắm nếu bạn chỉ muốn viết chương trình nên bạn có thể bỏ qua. Tuy nhiên, nó lại khá hay và hơi phức tạp vì có đụng nhiều tới toán học. Nếu muốn tìm hiểu về machine learning hoặc data mining thì bạn nên đọc qua nhé.
Training Set/Validation Set/Test Set
Các bạn có nhớ ở phần 3, mình đã khuyên các bạn bỏ 4 tấm ảnh đầu tiên để dành không? Thật ra đây là một thủ thuật phân chia dữ liệu hay dùng trong machine learning/data mining.
Giả sử bạn dạy phép cộng cho một đứa bé. Ban đầu bạn dạy nó 1+1 = 2, 2+2=4. Để đề phòng thằng bé học vẹt, khi kiểm tra bạn sẽ không hỏi 1+1 bằng mấy mà hỏi 1+2 bằng mấy, nếu nó trả lời được tức là đã hiểu.
Trong machine learning cũng vậy. Để tránh tình trạng thuật toán “học vẹt”, chạy đúng với dữ liệu đã train nhưng không đúng với dữ liệu mới (còn gọi là overfitting), người ta chia dữ liệu làm training set, validation set và test set:
- Training set là dữ liệu dùng để huấn luyện cho mô hình.
- Validation set là dữ liệu để tinh chỉnh mô hình, so sánh các mô hình khác nhau.
- Test set là dữ liệu cuối cùng để đánh giá độ chính xác của mô hình.
Ví dụ, bạn Trườn đang dạy một bé ngực khủng chân dài lớp 12 thi đại học:
- Kiến thức hằng ngày bạn dạy cho bé chính là training set.
- Sau khi dạy, bạn cho bé làm bài kiểm tra mỗi tuần. Các đề bài kiểm tra này chính là validation set. Bạn dựa vào các kết quả này để đánh giá trình độ bé, quyết định nên dạy thêm phần nào, bớt phần nào để tăng điểm số (tăng độ chính xác).
- Đề thi đại học chính là test set, đây là kết quả học hành của bé.
Trong bài mình chỉ chia dữ liệu ra làm 2 phần là training set và test set cho đơn giản vì ta chỉ có 1 model, việc tuỳ chỉnh cũng đã được Microsoft API thực hiện.
Tìm hiểu thêm về test set và overfitting:
Nhắc lại vài khái niệm toán học
Trong machine learning, để đánh giá độ chính xác của một thuật toán, người ta dùng một bảng gọi là confusion matrix (hoặc matching matrix). Để hiểu bảng này ta cùng nhớ lại một chút kiến thức “học thuật” về môn Xác Suất Thống Kê nhé.
Quay lại với em gái ngực khủng phía trên. Sau khi kèm em đỗ Đại Học, hai người quyết định vào nhà nghỉ để ăn mừng. Vài hôm sau thì bỗng dưng bạn Trườn thấy ngứa chỗ không nên ngứa. Bạn hoảng sợ, vội vàng đi khám bác sĩ da liễu, nhầm, … hoa liễu. Kết quả sẽ là một trong bốn trường hợp sau:

Các bạn đọc lại một số link này để nhớ các khái niệm TP, FN, FP, TN trong bảng trên nhé:
- http://www.mathsisfun.com/data/probability-false-negatives-positives.html
- https://sites.google.com/site/diepnn80/datamininginfo/cacdodohaydungchobaitoanphanloai
Kết quả đo đạc
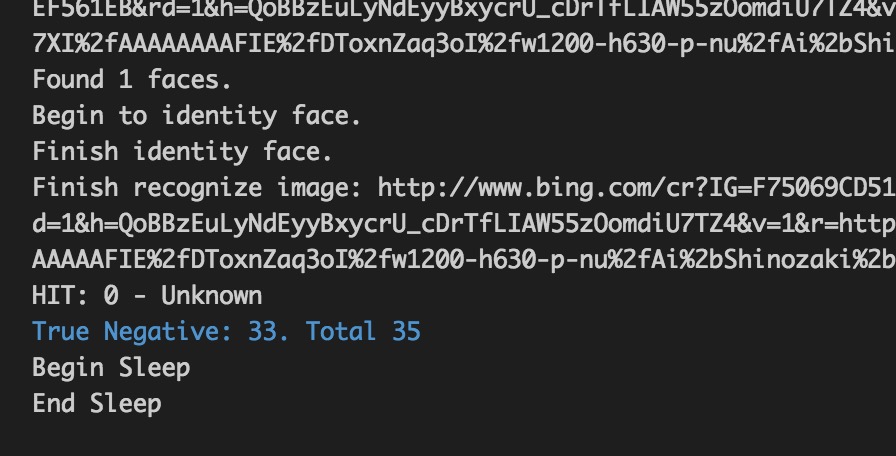
Để đánh giá độ chính xác của thuật toán, mình cần có con số True Positive và True Negative để dựng nên Confusion Matrix. Code phần này cũng không có gì đáng học hỏi nên các bạn cứ đọc trong file test.js trong repo của mình là được.
Kết quả khi mình dùng API để nhận diện 48 tấm ảnh của 12 idol đã huấn luyện (Một vài ảnh không có mặt hoặc link bị lỗi). Có thể thấy model của chúng ta nhận diện đúng được 40/42 tấm.

Kết quả khi mình chạy với 4 idol không có trong cơ sở dữ liệu (Gồm: Sơn Tùng, Tùng Sơn, Maria Ozawa, Ai Shinozaki). Model có performance khá ổn khi nhận được đúng 33/35 tấm.
Confusion Matrix kết quả của thuật toán:
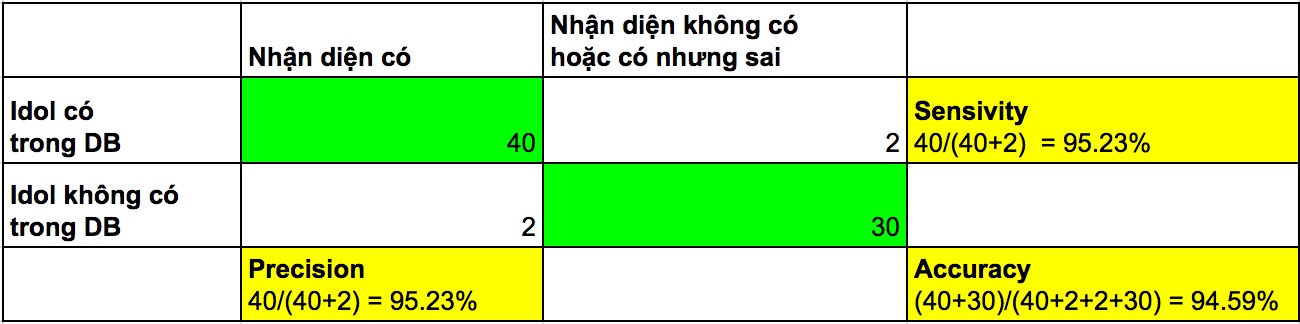
Có khá nhiều giá trị để đánh giá, chúng ta quan tâm đến các giá trị sau đây:
- Sensivity [TP / (TP + FN)] – Với 42 ảnh có trong DB thì nhận dạng được 95.23% đúng.
- Precision [TP / (TP + FP)] – Với 42 kết quả nhận diện có, có 95.23% kết quả là chính xác.
- Accuracy [(TP + TN) / (TP + FP + TN + FN)] – Độ chính xác tổng thể là 94.59%.
Lưu ý: Do trong demo này chúng ta chỉ dùng 12 idol và mỗi idol có khoảng 20 hình chất lượng cao nên độ chính xác cao như vậy. Trong Nhận diện Idol, dữ liệu có tới 500 idol, kích thước hình hơi nhỏ và… bị biến dạng bởi nhiều “vật thể lạ” và các “yếu tố khách quan” nên độ chính xác không cao bằng.
Kết
Ở phần này, chúng ta đã viết xong một hàm chạy bằng NodeJS để nhận diện Idol trong ảnh. Tuy nhiên, API này chỉ chạy được để demo ở máy bạn.
Làm sao có thể biến nó thành RestAPI để có thể dùng được nhiều nơi (Di động, web) và hiển thị các kết quả lên Web? Hãy cùng đón xem phần cuối của Series Nhận diện idol – Từ demo đến deploy. Cố lên nhé, chỉ còn 1 kì cuối nữa thôi!
Sản phẩm cuối cùng của chúng ta sẽ tương tự như sau: http://jav-idol.toidicodedao.com/vav/.
Discover more from Từ coder đến developer - Tôi đi code dạo
Subscribe to get the latest posts sent to your email.

cho em hỏi có cách nào cho nó nhận dạng thông qua camera được không ạ ? em chỉ mới tìm hiểu thôi nên câu hỏi hơi * ngây thơ * tí mong ad thông cảm .
LikeLiked by 1 person
Hehe lại chung ý tưởng. Cái đó thì lại phải tự động nhận diện khuôn mặt. Khi camera nhận diện được điểm ảnh là khuôn mặt thì kèm theo đó là nó đang chạy code để phân biệt rồi !
LikeLike