
Bài viết gồm 3 phần:
- Phần 1: Làm quen với puppeteer
- Phần 2: Dùng puppeteer để cào dữ liệu và vếu từ mương14.
- Phụ lục: Tổng quan về testing và automation test
- Phần 3: Viết Automation test với Puppeteer
Ở phần trước mình đã hướng dẫn cách cài đặt Puppeteer rồi nên phần này chúng ta bắt tay vào code ngay luôn cho nóng nha.
Hôm nay chúng ta sẽ tìm hiểu về API của Puppeteer, sau đó cùng nhau cào tin tức và vếu từ mương 14 nhé.
Giới thiệu về API của Puppeteer
Do Pupetter là một công cụ khá mạnh mẽ nên API của nó cũng hơi nhiều và dài dòng (Giống Photoshop mạnh mẽ như khó học vậy đó).
Tuy vậy, may mắn là các API này không quá phức tạp, chúng đều đã được document cẩn thận tại đây: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md.
Các bạn có thể vào đọc sơ nhé. Chia sẻ luôn, một trong những cách hay nhất để tìm hiểu công nghệ mới là lên trang web của nó để xem ví dụ và đọc API đó.

Trong pham vi bài viết, chúng ta chỉ quan tâm tới một số api chính:
- puppeteer.launch: Mở trình duyệt Chrome lên để bắt đầu làm trò. Hàm này trả về object kiểu Browser.
- browser.newPage: Mở một tab mới trong Chrome để làm trò. Hàm này trả về object kiểu Page.
- browser.close: Tắt trình duyệt (Đỡ phải tắt bằng tay)
- page.goto: Đi tới một trang nào đó. Có params waitUntil khá quan trọng. Params này quyết định chúng ta chờ tới khi page vừa mới load xong, hay sau khi page đã load toàn bộ JavaScript và hình ảnh.
- page.screenshot: Chụp ảnh tab hiện tại, lưu thành file ảnh.
- page.evaluate: Đây là API quan trọng nhất, cho phép ta chạy script trong browser và lấy kết quả trả về. Chúng ta sẽ dùng API này để cào mương 14 nhé.
Nào mình cùng đào móc mương 14
Tại sao lại cào ở kênh14, vì mình thích, ok. Chúng ta sẽ khởi động với màn lấy tiêu đề và url của các bài viết. Chỉ cần làm theo 3 bước đơn giản sau:
1. Trước khi code thật thì chúng ta tìm hiểu cấu trúc HTML của kenh14.vn đã nhé.
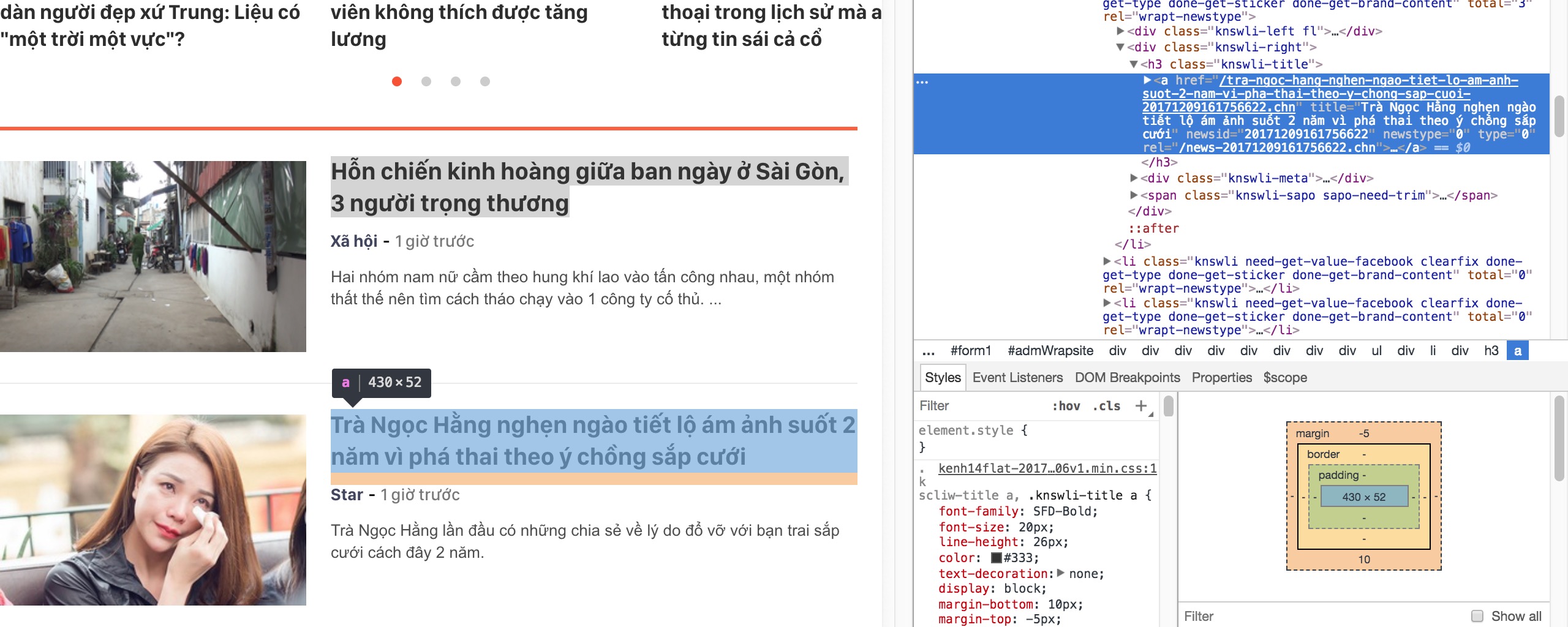
Các bạn có thể thấy, tiêu đề của các bài viết nằm trong element a, con của element h3 có class là knswli-title. URL nằm trong attribute href của element a đó luôn.
2. Chúng ta thử cào dữ liệu bằng cách viết code JavaScript trong của số console trước nào. Các bạn bấm qua tab console, dán đoạn code này và xem kết quả nhé. (Xem comment để hiểu code làm gì).
| // Select tất cả các element chứa tiêu đề bài viết | |
| let titleLinks = document.querySelectorAll('h3.knswli-title > a'); | |
| // Chuyển node list thành 1 mảng | |
| titleLinks = [...titleLinks]; | |
| // Với mỗi phần tử trong mảng, ta lấy attribute title và link, chuyển thành object | |
| let articles = titleLinks.map(link => ({ | |
| title: link.getAttribute('title'), url: link.getAttribute('href') | |
| })); |

3. Ok, code của chúng ta giờ đã chạy tốt, bây giờ chúng ta quay lại với project NodeJS của kì trước và bắt đầu viết nào.
| const puppeteer = require('puppeteer'); | |
| (async() => { | |
| // Mở trình duyệt mới và tới trang của kenh14 | |
| const browser = await puppeteer.launch({ headless: false }); | |
| const page = await browser.newPage(); | |
| await page.goto('http://kenh14.vn'); | |
| // Chạy đoạn JavaScript trong hàm này, đưa kết quả vào biến article | |
| const articles = await page.evaluate(() => { | |
| let titleLinks = document.querySelectorAll('h3.knswli-title > a'); | |
| titleLinks = [...titleLinks]; | |
| let articles = titleLinks.map(link => ({ | |
| title: link.getAttribute('title'), | |
| url: link.getAttribute('href') | |
| })); | |
| return articles; | |
| }); | |
| // In ra kết quả và đóng trình duyệt | |
| console.log(articles); | |
| await browser.close(); | |
| })(); |
Code của chúng ta sẽ mở Chrome lên, chạy đoạn code JavaScript phía trên, lấy kết quả và in ra và đóng trình duyệt.
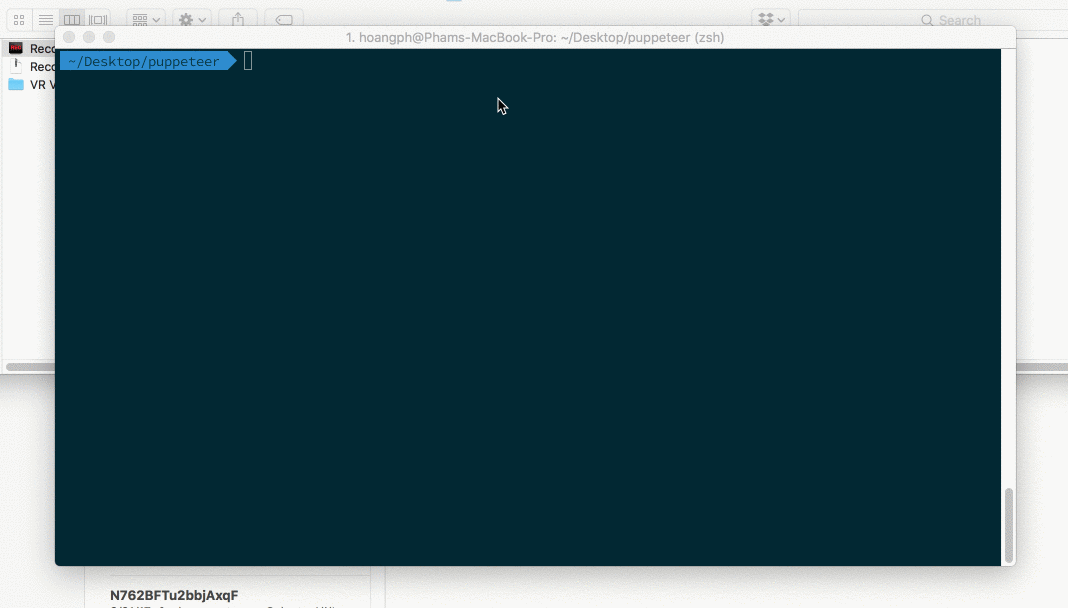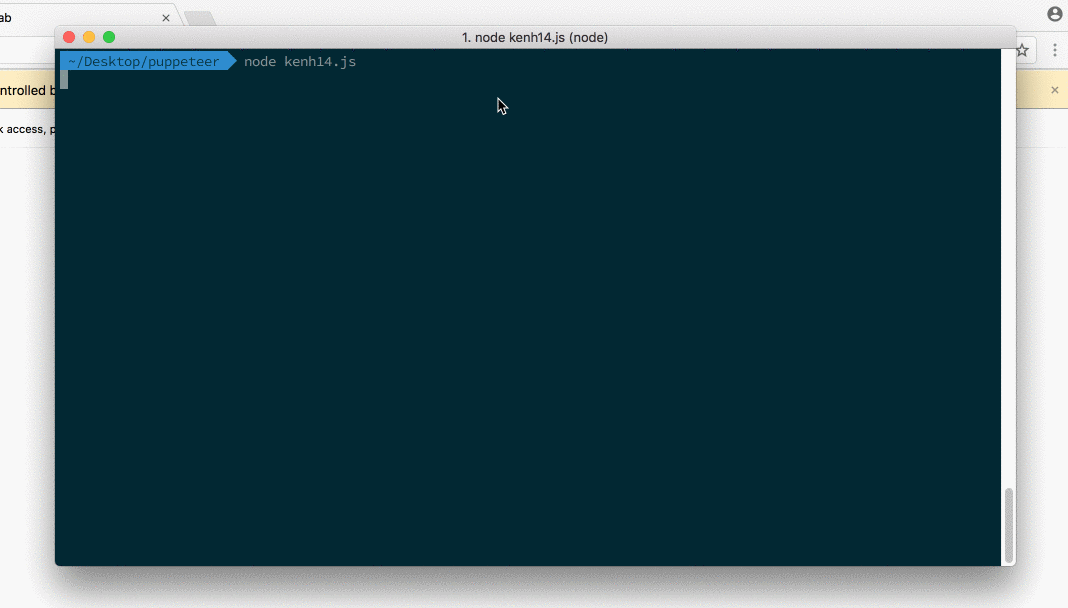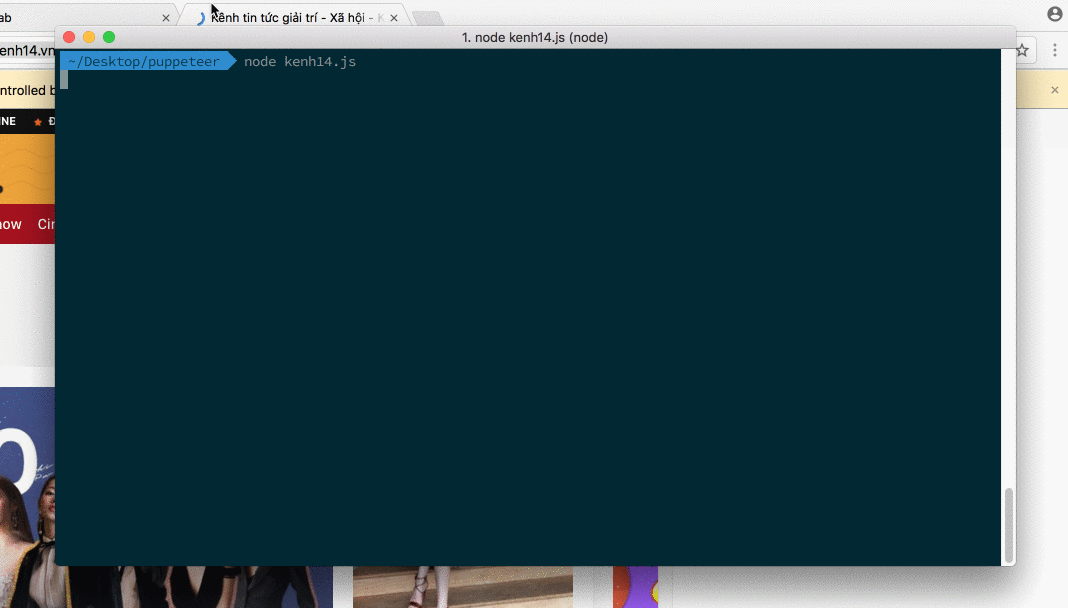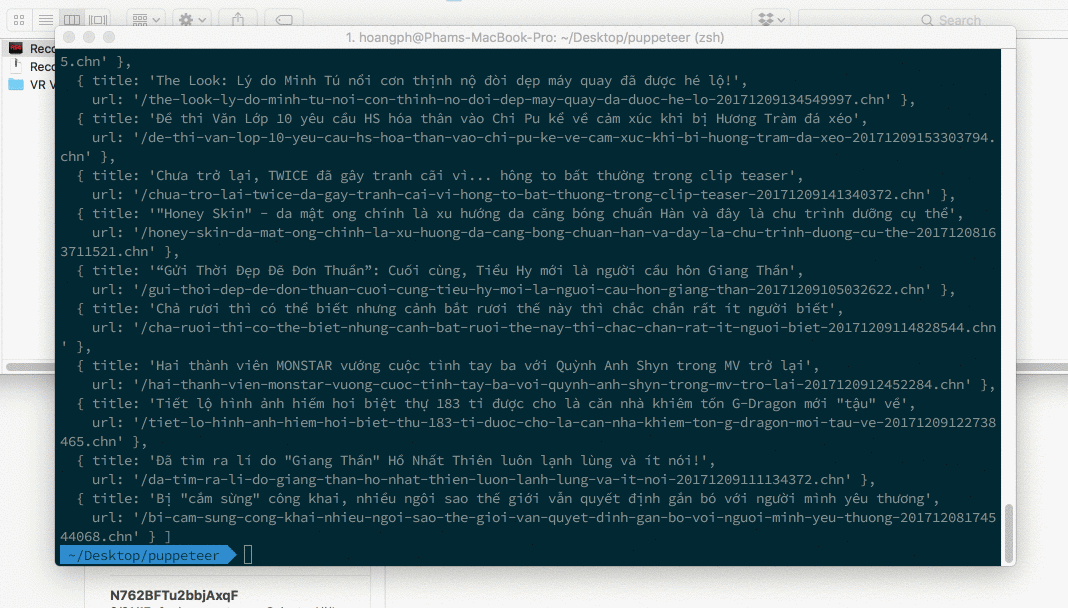
Phức tạp hơn, tải hình vếu về ngắm!
Từ đầu tới giờ, lúc chạy chương trình, mình để headless : false để các bạn dễ nhìn, thực ra ta có thể cho puppetter chạy ngầm mà không cần giao diện.
Lần này, chúng ta thử sức với một thử thách khó khăn hơn, đó là tải hết toàn bộ hình vếu trong bài viết này: http://kenh14.vn/ai-roi-cung-khac-cac-hot-girl-nay-cung-khong-ngoai-le-khi-vong-1-cu-ngay-cang-phong-phao-20171207193958533.chn

Quá trình này cũng chỉ gồm 3 bước:
- Vào trang phía trên
- Load các tag img, tìm link các ảnh đó
- Tải các ảnh đó về máy
Nào, chúng mình cùng bắt đầu thôi:
1. Sau khi mò HTML của trang, ta thấy các ảnh nằm trong thẻ a có class là sp-img-zoom, sp-img-lightbox, detail-img-lightbox. Khỏi cần test trong console mà bắt đầu code luôn.
2. Các bạn mở cửa số cmd của project hiện tại, gõ npm install –save image-downloader để thêm thư viện tải ảnh.

3. Code thôi nào. Các bạn thấy đấy, do chúng ta không set headless:false nên chrome chạy ngầm mà không cần giao diện luôn!
| const puppeteer = require('puppeteer'); | |
| const download = require('image-downloader'); | |
| (async() => { | |
| const browser = await puppeteer.launch(); | |
| console.log('Browser openned'); | |
| const page = await browser.newPage(); | |
| const url = 'http://kenh14.vn/ai-roi-cung-khac-cac-hot-girl-nay-cung-khong-ngoai-le-khi-vong-1-cu-ngay-cang-phong-phao-20171207193958533.chn'; | |
| await page.goto(url); | |
| console.log('Page loaded'); | |
| const imgLinks = await page.evaluate(() => { | |
| let imgElements = document.querySelectorAll('.sp-img-zoom > img, .sp-img-lightbox > img, .detail-img-lightbox > img'); | |
| imgElements = [...imgElements]; | |
| let imgLinks = imgElements.map(i => i.getAttribute('src')); | |
| return imgLinks; | |
| }); | |
| console.log(imgLinks); | |
| // Tải các ảnh này về thư mục hiện tại | |
| await Promise.all(imgLinks.map(imgUrl => download.image({ | |
| url: imgUrl, | |
| dest: __dirname | |
| }))); | |
| await browser.close(); | |
| })(); |
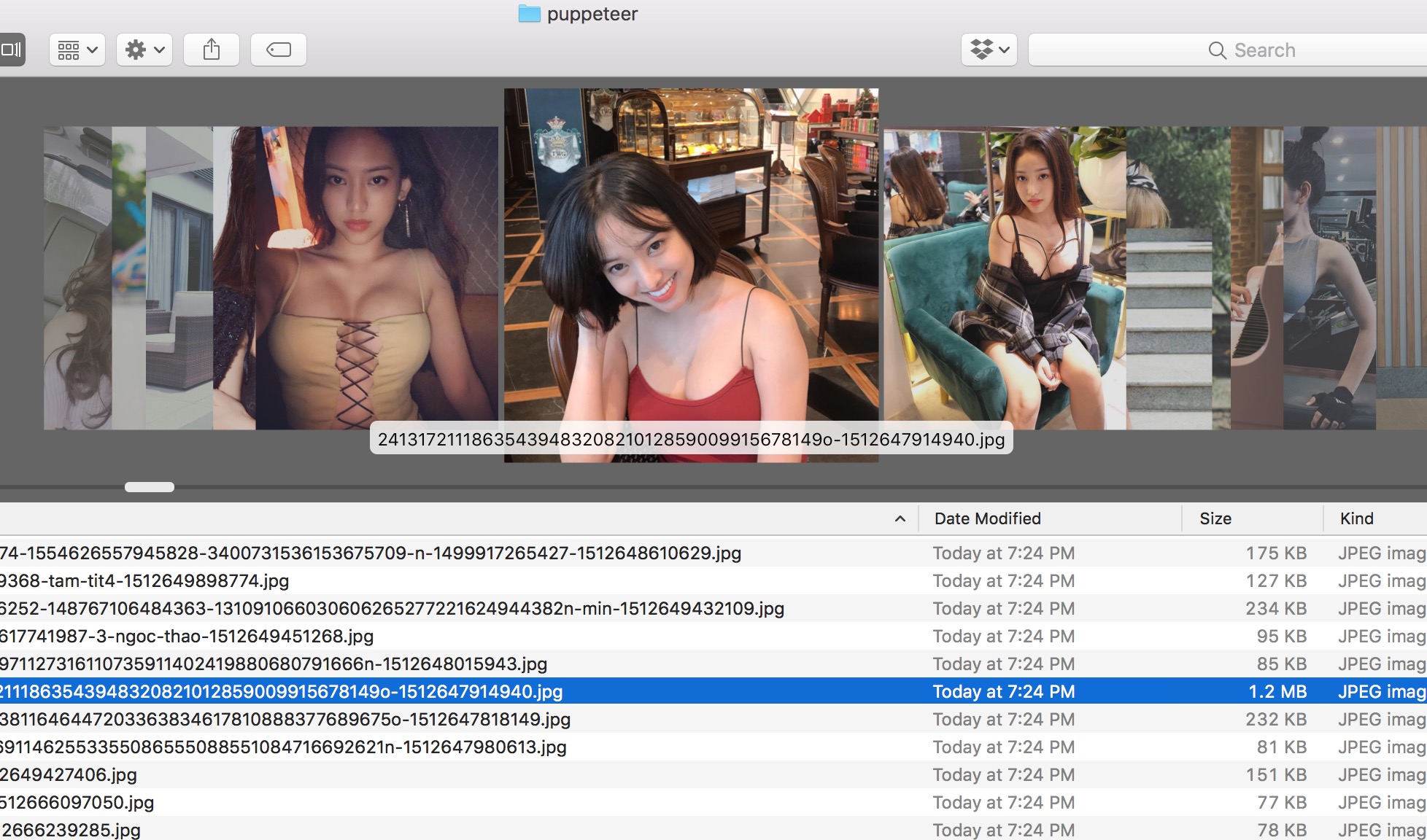
Kết
Chúc mừng các bạn đã hoàn thành một bài tutorial khá khoai và dài hơi. Như các bạn thấy đấy, dùng puppeteer để cào dữ liệu có thể cào luôn được cả AJAX và các trang chứa JavaScript, rất tiện lợi.
Tuy nhiên, sức mạnh của puppeteer không chỉ có thế! Ở phần sau, mình sẽ cùng các bạn tìm hiểu về automation test và cách dùng pupeteer để viết automation test nhé.
Mọi thắc mắc các bạn cứ thoải mái comment trong bài viết nhé.
Discover more from Từ coder đến developer - Tôi đi code dạo
Subscribe to get the latest posts sent to your email.

Hóng phần sau của bác 🙂
LikeLike
lót dép đợi s2 của a. e đã thử, nhưng chưa biết cách làm sao để set window size = viewport size.
LikeLike
Set viewport size là đủ rồi e nhé. Sau này mình chạy headless nên ko cần mở window lên làm gì hihi 😀
LikeLike
ahihi, cũng tại em muốn nhìn nó chạy như thế nào. em có dùng selenium để viết auto upload cho mấy trang bán áo thun. giờ thấy a chia sẻ thằng này nên e muốn tìm hiểu xem nó ngon hơn không.
LikeLike
Hi Hoàng, Cảm ơn Hoàng bài viết này. Hiện mình muốn thử tự làm 1 chrome extension sử dụng code của bài viết này. Giả sử download toàn bộ 1 ảnh từ 1 bài viết của Kênh 14 chằng hạn (người dùng nhập URL vào) thì có được ko nhỉ?
LikeLike
Chrome extension thì dùng code khác bạn nhé 😉
https://developer.chrome.com/extensions/downloads
LikeLike
Thế nào mà em test trên Chorme lại không ra được mảng như thế mà chạy code lại vẫn cứ oke :v
LikeLike
Ahihi do ăn ở :3
LikeLike
làm thế nào để lọc được kết quả như anh vậy ạ? Của em nó ra rất nhiều thuộc tính luôn
http://www.upsieutoc.com/image/4DK0Nt
LikeLike
In ra biến articles mới đúng e nhé 😉
LikeLike
Anh Hoàng ơi làm bài viết về career path và quá trình tích lũy kiến thức của anh đi 😀 😀
LikeLike
Quá trình làm việc của a thì e xem trong mục About Me nhé 😉
LikeLike
Hóng part 3 bác ơi
LikeLike
Sự khác nhau giữa cái này và selenium là gì hả các bác
LikeLike
Chờ phần 3 sẽ biết e nhé 😉
LikeLike
Anh ơi, em làm xong thì bị lỗi như trong hình, là do gì vậy anh.
https://upanhtocdo.com/image/iaLv
LikeLike
Anh có thể làm demo 1 ví dụ về việc lấy dữ liệu trong trường hợp load ajax chẳng hạn như nút xem thêm k anh? Hay anh cho em ý tưởng cách làm với ạ.
LikeLike
E xem phần 3 nhé 😉
LikeLike
anh có thể viết bài về giao thức DevTool của chrome ko.
vì puppeteer nó quá dễ rồi. project nó cũng nói rõ là puppeter chỉ là cái để demo thôi.
em muốn implement trên một ngôn ngữ khác, nhưng đọc chả hiểu gì.
LikeLike
Hóng phần 3 của bác, mình đang bị vướng chỗ mấy trang web scrolling để load page @@
LikeLike
Anh ơi em là newbie laravel , em tạo file js và return kết quả ra console của trang blade . Nhưng lại bị lỗi này :
+ require.js:5 Uncaught Error: Module name “puppeteer” has not been loaded yet for context: _. Use require([])
Em vừa include require js vào file script của trang blade .
LikeLike
Nếu để cào dữ liệu là audio (.mp3,..) thì dùng module nào thay thế image-downloader vậy anh ?
LikeLike
Tìm cái nào tải được file thôi e 😀
LikeLike
ok cảm ơn anh, do mạng yếu, chèn thêm đoạn đợi link là ok
LikeLike
Uncaught SyntaxError: Identifier ‘titleLinks’ has already been declared
Hoàng ơi cho mình hỏi khi mình chép đoạn lệnh lên console thi nó báo lỗi này bạn à!
LikeLike
Anh ơi ạnh làm phần 3 demo cho ae cách lấy dữ liệu khi scroll và khi ấn xem thêm gửi request ajax được k a?
LikeLike
À puppeteer có API để scroll với click vào button đó em 😉
LikeLiked by 2 people
Làm 1 phần về cào AJax và các trang chưa Javascript đi anh ơi
LikeLike
tải ảnh về mà Status Code: 403 thì phải làm sao để tải về đc vậy anh
LikeLike