
Ở phần 2, bọn mình đã ôn lại những cấu trúc dữ liệu rất cơ bản như Array, LinkedList, Stack and Queue rồi. Ở phần này, tụi mình sẽ tìm hiểu thêm về các cấu trúc dữ liệu hay ho nhưng ít dùng hơn như HashTable, Set, Graph và Tree!
Mình sẽ giải thích sơ về độ phức tạp, ứng dụng của chúng, cũng như những bài toán các bạn hay gặp với các cấu trúc dữ liệu này nhé.
Đây là phần 3 trong series bài viết 3 phần:
- Ôn lại về Big-O Notitation, Time và Space Complexity
- Array, Linked List, Stack và Queue
- HashTable, Set, Graph và Tree
HashTable (Bảng băm) – CTDL bá đạo diệu kì
Độ phức tạp

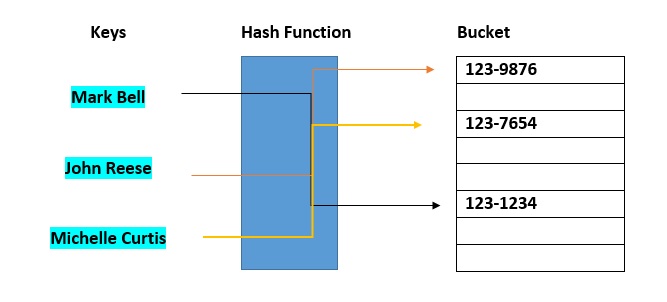
Khi đưa 1 phần tử vào HashTable, ta phải chỉ định 1 key (ví dụ lưu sinh viên thì key là mã số sinh viên). Khi cần truy cập 1 phần tử từ HashTable dựa theo key, độ phức tạp của việc tìm 1 phần tử là O(1). Đây là thứ tạo nên sự bá đạo của HashTable.
Khi lưu 1 phần tử vào HashTable, ta sẽ đưa key vào hash function (hàm băm). Hash function này sẽ tính ra một index để lưu phần tử đó vào. Khi cần tìm phần tử đó, ta cũng dựa vào key để tính ra index.
Dù hashtable có 1000 hay 1 triệu phần tử thì hàm băm cũng chỉ chạy 1 lần, khi đã có index thì thời gian truy cập chỉ là O(1).

Độ phức tạp (nâng cao)
Tất nhiên, sẽ có trường hợp hash collision, tức là 2 key khác nhau, nhưng hash function lại tính ra index giống nhau. Lúc này, ta phải lưu nhiều phần tử có chung index vào bucket, sau đó check từng phần tử một.
Do vậy, nếu để ý, các bạn sẽ thấy worse case vẫn là O(n), nếu toàn bộ phần tử của hashtable được lưu hết vào chung 1 bucket.
Trên thực tế, việc implement hashtable khá phức tạp (thuật toán hash ra sao, làm sao để các phần tử phân bố cân bằng vào bucket). Nhiều nơi tuyển senior họ sẽ hỏi sâu hơn, các bạn nên tìm hiểu thêm nhé! (Ông bạn mình đi PV tại ByteDance – TikTok bị hỏi luôn).
Ứng dụng
Do độ phức tạp của insert/access/delete là O(1), HashTable được sử dụng rất nhiều khi ta cần optimize tốc độ truy cập. Một số key-value cache server cũng được design dựa theo cấu trúc dữ liệu này: đưa vào 1 key, cache server sẽ trả lại dữ liệu đã được lưu.
Các ngôn ngữ phổ biến như Java, C# đều có class Hashtable (hoặc tên khác là HashMap, Dictionary). JavaScript thì gần đây mới có Map, trước toàn phải dùng object.
Một số bài toán hay gặp
- Các bài toán sử dụng vòng lặp, đếm số phần tử xuất hiện trong 1 mảng
- Tìm các phần tử giống nhau giữa 2 array
- Tự implment 1 hashtable (chọn thuật toán hash và gỉải thích)
- https://leetcode.com/tag/hash-table
Set – Nơi các phần tử không đụng hàng
Set là một tập hợp chức nhiều phần tử không theo thứ tự, mà mỗi phần tử trong đó không được trùng nhau.
Độ phức tạp và ứng dụng
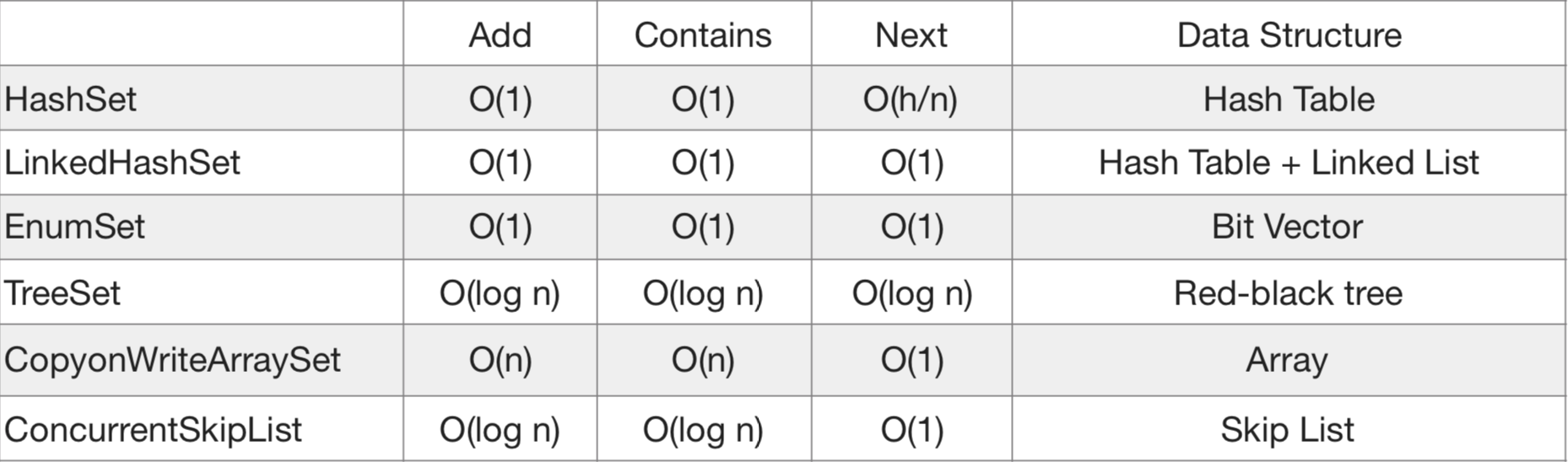
Set thật ra không phải là một cấu trúc dữ liệu, mà nó chỉ là abstract data type. Có rất nhiều cách để implement 1 set như dùng HashYable, Linked List, Tree v…v, mỗi cách sẽ có độ phức tạp riêng.
Do đặc tính lưu các phần tử không trùng nhau của mình, set thường được dùng để lưu trữ các IP/các trang web đã truy cập. Do tìm kiếm 1 phần tử trong Set chỉ có độ phức tạp O(n) nên ta có thể dùng để blacklist/whitelist IP dựa theo danh sách có sẵn luôn.
Một số bài toán hay gặp
- Loại bỏ các phần tử bị trùng trong 1 mảng
- Gộp 2 array lại với nhau, loại các phần tử trùng lặp
- Tìm các phần tử giống nhau/khác nhau giữa 2 array
Graph – Đồ thị không kì dị
Đồ thị là một cấu trúc dữ liệu khá phức tạp, nhiều nơi tách hẳn ra 1 môn môn “Lý thuyết đồ thị” luôn! Nói đơn giản, một đồ thị là một tập hợp gồm nhiều điểm (vertical), các điểm này nối với nhau bằng các cạnh (edge).
Ứng dụng
Mình làm về mảng web, nên đi làm hơn 6 năm tới giờ mình chưa cần dùng tới đồ thị để giải quyết bất cứ chuyện gì. Đi phỏng vấn cũng chưa bị hỏi thuật toán về đồ thị, chắc ở tầm Amazon/Facebook/Google họ mới hỏi.

Tuy vậy, ở những mảng khác, đồ thị được dùng để giải quyết rất rất nhiều vấn đề hay ho:
- Tìm đường đi ngắn nhất từ điểm A tới B (ứng dụng bản đồ, truyền gói tin)
- Tìm bạn bè chung, người quen trên mạng xã hội
- Tìm quan hệ giữa các trang web để đánh giá độ tin cậy (Thuật toán PageRank của Google)
Một số bài toán hay gặp
- Tìm đường đi ngắn nhất/qua ít node nhất từ điểm A tới B
- Duyệt qua toàn bộ các điểm của đồ thị (Dùng Deep First Search/Breath First Search)
- https://leetcode.com/tag/graph
Tree – Cây gì không lá không quả, nhưng vẫn hữu dụng
Tree (Cây) cũng là một dạng đồ thị:
- Một cây sẽ có 1 node gốc (root).
- Mỗi node sẽ có 1 hoặc nhiều node con.
- Những node nào không có node con được gọi là leaf note
- Một cây sẽ bao gồm nhiều cây con (subtree). Mỗi cây con sẽ gồm 1 node gốc và các node con của nó.
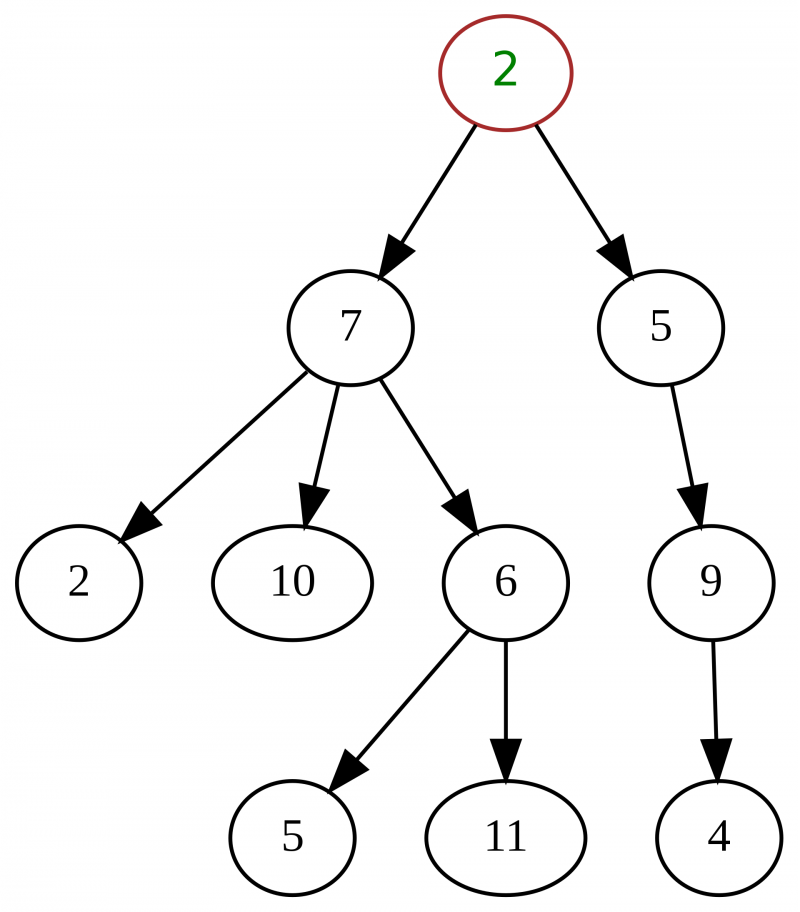
Tree có 2 biến thể phổ biến và được dùng nhiều nhất:
- Binary Tree: Mỗi node sẽ có tối đa 2 con, lần lượt gọi tên là node trái và node phải
- Binary Search Tree: Biến thể của Binary Tree. Các phần tử trong subtree bên trái phải nhỏ hơn node giữa, bên phải phải lớn hơn node giữa. Mỗi cây con của cây phải là Binary Search Tree

Ngoài ra, Tree cũng còn có khá nhiều biến thể như Trie, Red-Black Tree,… mình cũng chỉ nghe nói chứ chưa dùng bao giờ.
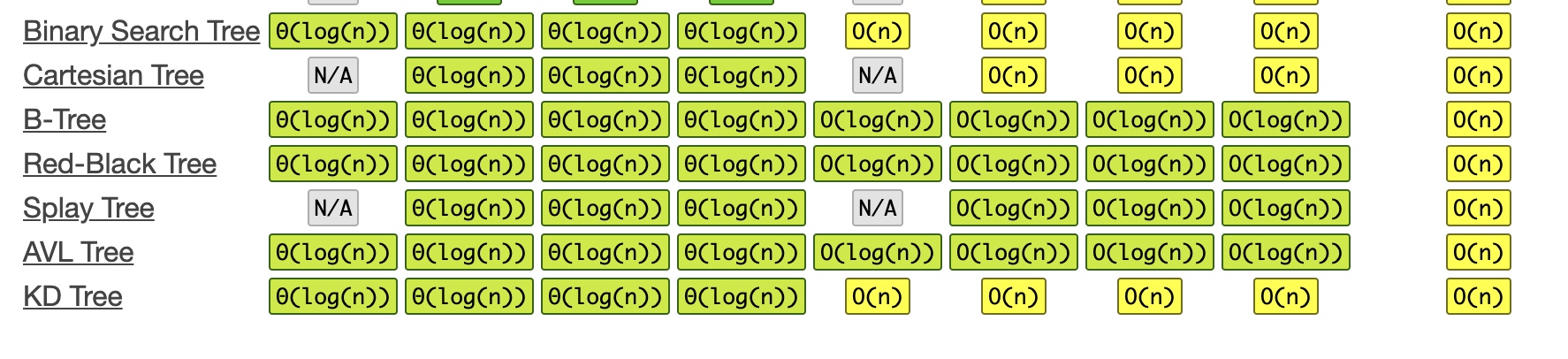
Ứng dụng
Tree được ứng dụng rất rất nhiều trong ngành lập trình:
- Parse source code của các ngôn ngữ ra thành syntax tree để xử lý
- Cây DOM của HTML cũng là 1 tree, với 1 node cha và nhiều node con
- Sử dụng binary search tree để lưu trữ dữ liệu, tìm kiếm với độ phức tạp O(logn)
Cá nhân mình đi làm cũng không cần phải implement Tree. Tuy vậy, trong quá trình phỏng vấn thì gặp những câu hỏi bắt sử dụng Tree khá nhiều. Do vậy các bạn cũng nên ôn nhé!
Một số bài toán hay gặp
- Duyệt các phần tử của cây (Dùng DFS/BFS)
- Kiểm tra 1 cây có phải là cây nhị phân, cây cân bằng hay không? Viết code cân bằng cây
- Tạo 1 array từ cây. Biến 1 array đã sort thành binary search tree
- https://leetcode.com/tag/tree
Tạm kết
Sau 3 phần của series này, các bạn đã ôn lại được kha khá kiến thức về các cấu trúc dữ liệu hay dùng rồi đấy! Có thể bạn sẽ không áp dụng 100% số đó trong công việc, nhưng chúng sẽ rất hữu ích khi bạn đi phỏng vấn, hoặc cần optimize một số đoạn code.
Đấy là mới chỉ nói về cấu trúc dữ liệu, còn về thuật toán thì còn bao la hơn nữa (qui hoạch động, chia để trị, tham lam, quay lui ….). Nếu quan tâm thì bạn cứ để lại comment, nếu có nhiều bạn quan tâm thì mình sẽ làm tiếp về tụi nó nhé.
Bonus: Các bạn có thể xem thêm vlog giải thích với khuôn mặt đập chai của mình tại đây.
Discover more from Từ coder đến developer - Tôi đi code dạo
Subscribe to get the latest posts sent to your email.

Hay lắm a ơi, làm tiếp a ơi
LikeLike
hay
LikeLike
Anh ơi, làm data phải học tree phải k ạ.
LikeLike